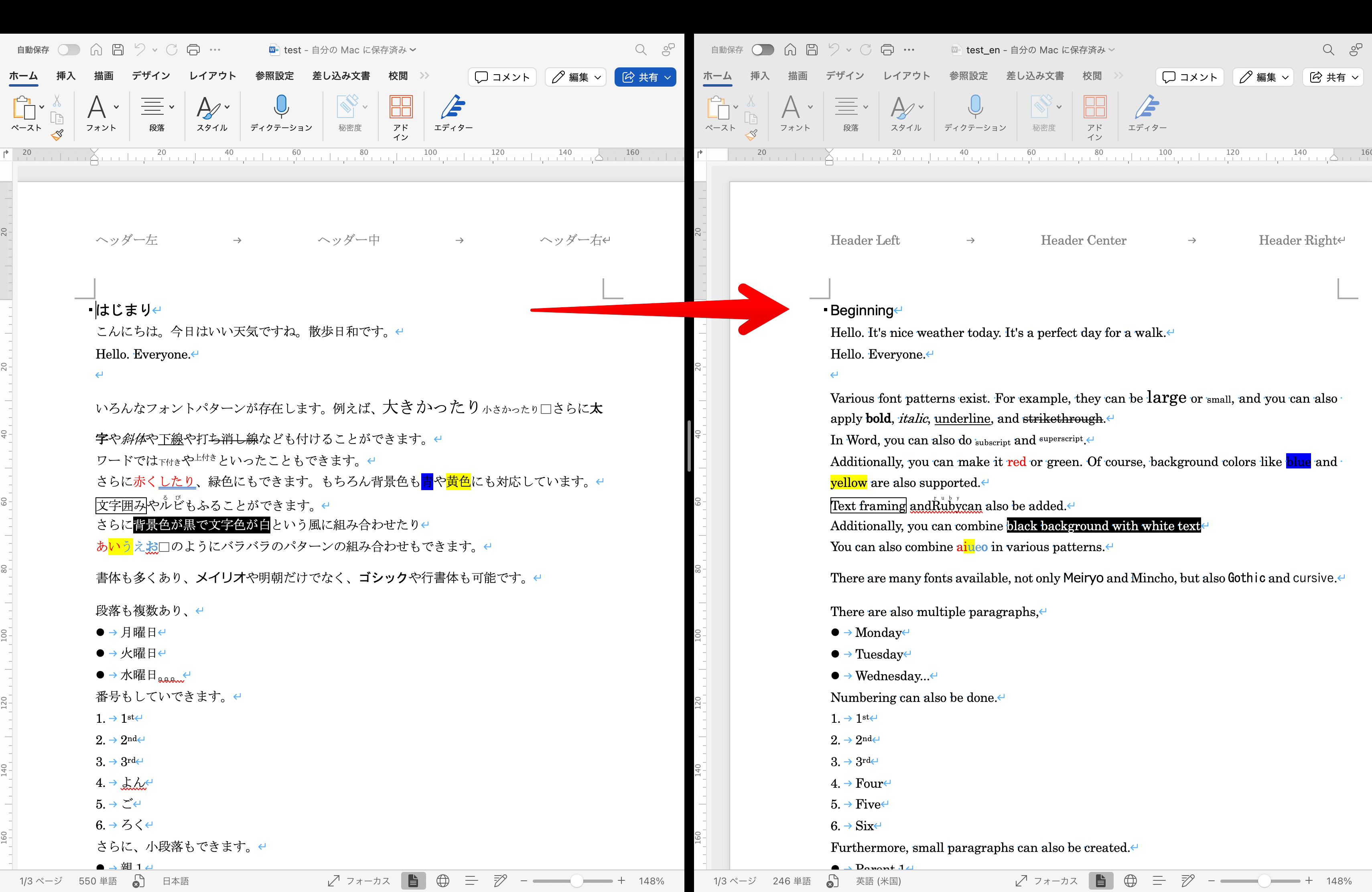
現代のビジネス環境では、ドキュメントの多言語対応が求められる場面が増えています。特に、企業が国際的に展開する際には、ドキュメントの正確な翻訳と書式の維持が重要です。ここで紹介するのが、LDX hub DocFlexテクノロジです。この技術は、ドキュメントの書式を維持しながら翻訳・変換を行うことを可能とします。DocFlexがどのようにしてこのプロセスを実現しているのかを詳しく見ていきます。

[図: LDX hub DocFlex機能を活用した機械翻訳の例]

※画像拡大は、画像で右クリックしショートカットメニューから[新しいタブで画像を開く]もしくは[画像の拡大]をクリックしてください。
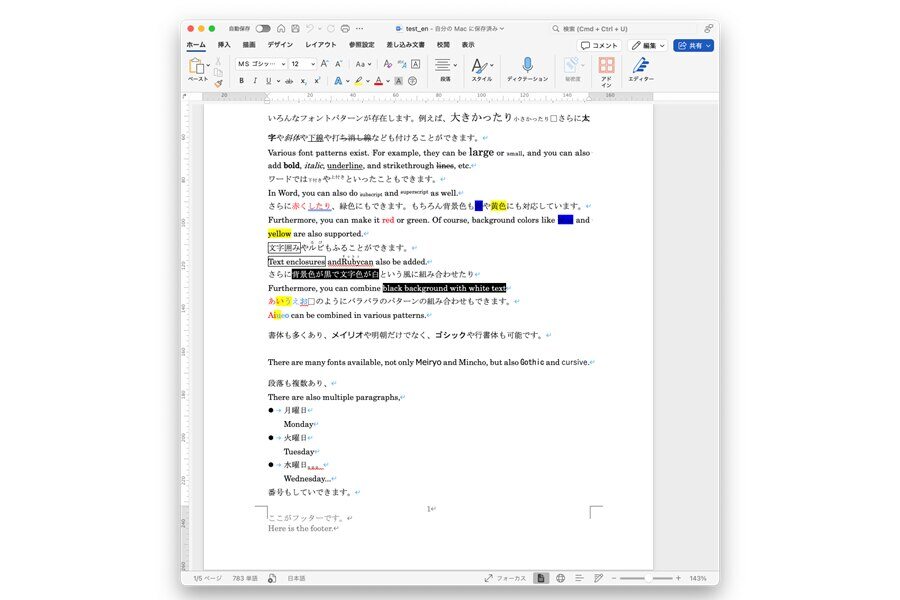
[図: LDX hub DocFlex機能を活用した常体(だ・である調)への変換結果の例]

※画像拡大は、画像で右クリックしショートカットメニューから[新しいタブで画像を開く]もしくは[画像の拡大]をクリックしてください。
ドキュメントのセグメント化
最初のステップは、ドキュメントに含まれるすべてのセグメントを1つの処理単位(A1)としてピックアップすることです。これにより、ドキュメント全体を一度に処理するのではなく、個々のセグメントごとに処理を行うことが可能となります。
A1例
|
[書式情報1]こんにちは。[書式情報2]ABCDE.[構造情報1]さようなら。 |
変換対象外の書式情報とテキストの保護
次に、処理単位(A1)に含まれる変換対象外の書式情報とテキストを保護ブロックに置き換え、処理単位(A2)とします。これにより、翻訳や変換の過程で保護されるべき書式情報が失われることを防ぎます。
A2例
|
[書式情報1]こんにちは。[保護ブロック1][構造情報1]さようなら。 |
セグメントの分割と参照ブロックの生成
処理単位(A2)をセグメント分割対象ごとにわけ、それぞれを原文(B1)としてリストアップします。また、処理単位(A2)に含まれる原文(B1)を参照ブロックに置き換えます。
A2例
|
[書式情報1]こんにちは。[保護ブロック1][構造情報1]さようなら。 |
B1例(1)
|
[書式情報1]こんにちは。[保護ブロック1] |
B1例(2)
|
さようなら。 |
翻訳・変換の実施
すべての原文(B1)を翻訳・変換し、それぞれを結果(C1)としてリストアップします。このステップでは、機械翻訳や生成AIによる翻訳や変換が行われます。
構造の評価
翻訳された結果(C1)を原文(B1)と比較し、構造上の破損がないかを評価します。問題のある結果(C1)はリストから破棄されます。
結果のマージ
処理単位(A2)に結果(C1)をマージします。翻訳・変換されたテキストが元のドキュメントの構造に組み込まれます。
A2例
|
[書式情報1] Hello. [保護ブロック1][構造情報1] Good-bye. |
余分な空白の除去
変換処理や対象言語の特性に従って、余分な空白を除去します。ドキュメントの見た目が整えられます。
変換対象外の書式情報とテキストの復元
処理単位(A2)に変換対象外の書式情報とテキストを復元します。ドキュメントの書式が元の状態に戻ります。
A2例
|
[書式情報1] Hello. [書式情報2]ABCDE.[構造情報1] Good-bye. |
不完全な復元の処理
構造上の破損が原因で復元が完全でない処理単位(A1)をリストアップし、書式情報や構造情報を保護・迂回した処理に回します。これにより、最終的なドキュメントの品質が保証されます。
まとめ
このように、LDX hub DocFlexは、ドキュメントの書式を維持しながら翻訳・変換を行うための高度なプロセスを提供します。特に生成AIとの高い相性を持つことで、次世代のドキュメント品質基準を実現します。
前の記事

LDX hub: 生成AIを使ったテキスト変換処理のコツ
次の記事
LDX hub: ドキュメント翻訳・変換時に原文を元のレイアウトに残す「対訳形式で出力」機能




で強化する情報セキュリティ|導入時の注意点とトラブル対策")