
弊社が運用している機械翻訳活用プラットフォーム「XMAT(トランスマット)」をご存じでしょうか?本記事では、すでにXMATをご利用いただいている方、また、初耳だよという方にも、知って得する「用語集を活用する方法」をご紹介します。
XMATについてはこちらのご案内ページをご確認いただくとして…。皆さんは翻訳の「用語集」と聞いてどんなもの(情報)を想像しますか?あるいは、日頃「用語集」をどのようにお使いでしょうか?
用語集とは
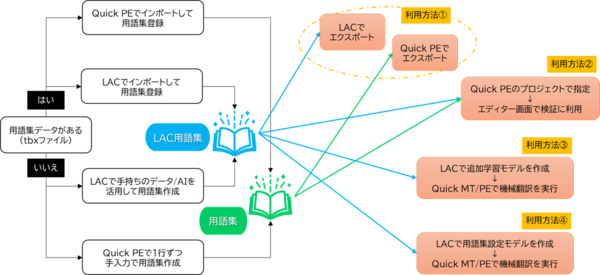
XMATで用語集を作成して利用する方法を図にしてみました。XMATで扱う「用語集」は、実際のデータとしては拡張子が「tbx」のファイルになります。中身は、翻訳元言語での用語(原文)と翻訳先言語での用語(訳文)が対になったもの、すなわち用語の対訳データです。
「用語集」という言葉で想像するデータ量(件数)は人や用途によりまちまちだと思いますが、XMATでは、10件だけの用語集でも10,000件ほどある用語集でも取り扱うことができます。ただし、目的によっては一定数以上の対訳データが必要になります。
※LAC(Language Asset Creator)は、XMATの有償オプション機能であり、言語資産作成と機械翻訳エンジンカスタマイズ作成の機能を備えています。LAC用語集およびLACの機能は、LACサービスをご契約いただいている場合のみご利用いただけます。機能の特長をマンガで解説はこちら。
目次[非表示]
- 1.用語集とは
- 2.用語集データの作り方
- 3.用語集の利用方法
- 3.1.利用方法① tbxファイルとしてエクスポート
- 3.2.利用方法② Quick PEエディター画面で検証に利用
- 3.3.利用方法③ LACで追加学習モデルを作成
- 3.4.利用方法④ LACで用語集設定モデルを作成
- 4.用語集を効果的にご利用いただくために
- 5.まとめ
用語集データの作り方
お手元にtbxファイルがある場合はそのままインポートしてXMATで使うことができます。Quick PEの用語集管理メニュー、またはLACの言語資産登録メニューをご利用ください。
XMAT Quick PE 用語集キャプチャ画面
tbxファイルをお持ちでない場合でも大丈夫。Quick PEの用語集管理メニューでは、対訳データを1件ずつ登録してゼロから用語集を作成できます。ただし、この場合はすべて手動での入力となるため、件数が増えるほど作成の手間も増えます。
一方、LACの言語資産登録メニューでは、一般的なファイル形式(xlsx、csvなど)の対訳データを用語集(tbx)に変換したり、バイリンガルファイル(xliffなど)から用語を抽出して用語集を生成したりと、Quick PEよりも簡単に大容量の用語集を作成することができます。
Quick PEもLACも対訳データの編集機能を備えていますので、対訳データの追加/削除や、原文/訳文の変更をXMAT上で行うことができます。
次に、こうして完成した用語集を利用する方法を4つご紹介します。
用語集の利用方法
利用方法① tbxファイルとしてエクスポート
用語集の利用方法として最もシンプルなのは、tbxファイルとしてエクスポートすることです。Quick PEでもLACでもエクスポートが可能です。(ただし、トライアル契約中は、LAC用語集のエクスポートはご利用いただけません。)
tbxは標準的な形式であり、多くのCATツールで読み込むことができますので、お客様の環境で自由にご利用いただけます。
利用方法② Quick PEエディター画面で検証に利用
Quick PEのグループで用語集を選択し、さらに、グループに属するプロジェクトで用語集を指定してエディター画面での検証に利用します。
用語集に登録されている用語が原文内に存在する場合、その用語の訳文が検証エリアに表示されて、ユーザーは手作業で翻訳の確認や修正を行うことができます。

ただし、この方法では、用語集に登録した翻訳が訳文に自動的に反映されることはありません。用語集に登録した翻訳を自動的に反映するには、利用方法④「用語集設定モデル」をご利用ください。
利用方法③ LACで追加学習モデルを作成
LACで追加学習モデルを登録する際に、教師データとして用語集を与えることで、用語の翻訳の傾向が反映されたモデルを作成することができます。
作成したモデルを指定してQuick MTおよびQuick PEで機械翻訳を実行すると、用語集にある原文と似た原文を翻訳する場合、出力される訳文に用語集の対訳の傾向が反映されます。ただし、翻訳したい原文が長い文章の場合、効果は限定的であり、訳文の品質がかえって低下することもあります。用語集に登録した訳文を自動的に反映するには、方法④「用語集設定モデル」をご利用ください。
利用方法④ LACで用語集設定モデルを作成
LACで用語集を指定して用語集設定モデルを登録する方法です。
作成したモデルを指定してQuick MTおよびQuick PEで機械翻訳を実行すると、出力される訳文には用語集の翻訳が自動的に反映されます。すなわち、用語集に存在する用語については、用語集に登録されている訳文に置換されて出力されます。(ただし、利用する機械翻訳学習サービスによっては、機械翻訳の対象とする原文が同じでも、条件等によって用語の訳文に置換されない場合もあります。)

用語集を効果的にご利用いただくために
XMATで想定している用語集は、専門用語や製品名、固有名詞など、文脈で変化することがあまりない用語を集めたデータです。たとえば、英日の用語集を作成する場合、単数形と複数形、2つの原文(用語)を別の対訳データとして登録しておけば訳文を統一できますが、逆方向の日英の用語集の場合、1つの原文に2つの訳文を登録しても、機械翻訳において自動的に使い分けられることはありません。

また、現在の機械翻訳では、原文の中の単語同士のつながりを認識しながら翻訳していますが、用語集設定モデルで翻訳する場合、用語とほかの部分とのつながりが認識できません。そのため、一般的な名詞を含む用語集を設定したモデルを作成して翻訳すると、訳文の品質が低下することがあります。
以上のことから、文脈に応じて単数形/複数形や時制が変わるような用語は用語集には向いていないと言えます。
まとめ
本記事では、XMATでの用語集の作り方と利用方法をご紹介しました。有用な用語集を作成することができれば、もっと簡単に、機械翻訳の出力結果をより良いものにすることができます。特に、オプション機能であるLACをご利用いただくと、お手元にtbxファイルがなくても簡単に大容量の用語集を作成できますので、是非、ご検討いただければと思います。
関連記事
- 流行りのDeepLも使い放題!機械翻訳界の超新星「XMAT」とは⁉
- 新ブランド「XMAT(トランスマット)」の立ち上げとビジョン①新ブランド立ち上げの経緯
- 訳文はどう変わる?4種類のAI翻訳エンジンを比べてみた!
 2週間の無料トライアル期間で、すべての機能をお試しいただけます。
お申込みはこちら |
前の記事

ソフトウェアローカリゼーション:成功のための4つのヒント
次の記事

ソフトウェアローカリゼーションの隠れたコスト




で強化する情報セキュリティ|導入時の注意点とトラブル対策")